Beyond average: A new approach to multicalibration brings group fairness to web scale
John Barlow and Daniel Titherington introduce MCGrad (MultiCalibration Gradient Boosting), a powerful machine learning algorithm developed by researchers at Meta and Professor Milan Vojnovic that ensures model predictions are properly calibrated across vast numbers of overlapping subgroups.

What if your AI model looks fair, but only on average? A collaboration between researchers at Meta and Professor Milan Vojnovic of the Department of Statistics at the London School of Economics has tackled exactly this problem, producing a new algorithm that is already running at massive scale inside some of the world's most widely used digital platforms. The work, published as ‘MCGrad: Multicalibration at Web Scale’ at ACM KDD 2026, is a strong example of what industry-academic collaboration can deliver: rigorous algorithmic research meeting the demands of real-world scale.
The Problem: fairness that hides in the average
When a Machine Learning (ML) model predicts an 80% chance of something happening, we expect it to be right about 80% of the time. This property, ‘calibration’, underpins reliable decision-making in content ranking, digital advertising, recommender systems, and content moderation. Without it, models systematically over- or underestimate risk, with real consequences for users.
But here is the catch, a model can be well-calibrated on average while quietly failing specific groups. It might be overconfident for users in one country, underconfident for a particular age group, or badly miscalibrated for any number of segments that nobody thought to check. ‘Multicalibration’, introduced by Hebert-Johnson et al. (2018), is the stronger property that closes this gap, requiring a model to be calibrated simultaneously across all meaningful subgroups, including ones never explicitly defined. It originated in the study of group fairness, a branch of algorithmic fairness concerned with ensuring ML models perform consistently across subpopulations.
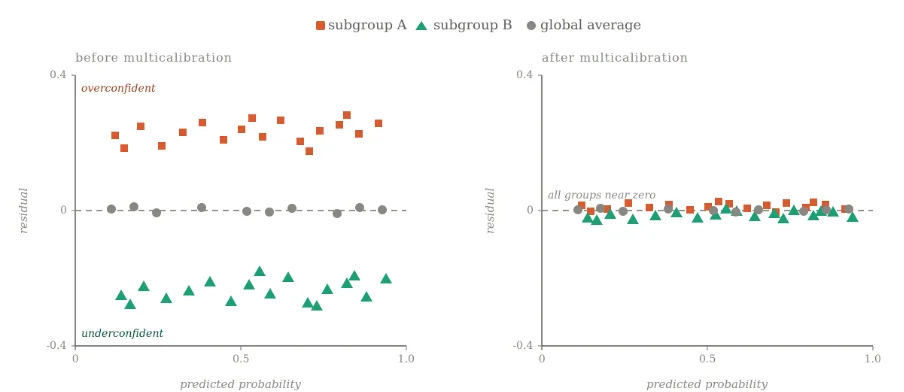
The concept had attracted significant academic attention. Yet it had never made it into production at scale. The LSE–Meta collaboration set out to understand why, and to change that.
Three barriers that kept multicalibration out of production
The team pinpointed three obstacles. First, existing algorithms required engineers to manually define protected subgroups, not just ‘age’ as a feature, but precise membership rules like ‘is the user an adult in the US?’ In practice, it is difficult to do this well, and definitions shift over time with legal and policy changes. Second, existing methods did not scale: computational cost grew linearly with the number of groups, making them impractical at web scale. Third, and perhaps most critically, they offered no safety guarantee. A miscalibration correction could inadvertently hurt overall model performance, a risk production teams simply would not take.
MCGrad: Designed for the real world
MCGrad (MultiCalibration Gradient Boosting) was built to overcome all three. Its key insight is deceptively simple: by including the base model's own predictions as an additional input feature, a Gradient Boosted Decision Tree can automatically find the regions of the input space where the model is miscalibrated, with no group definitions needed. The algorithm runs in successive rounds, each one refining the corrections of the last, converging toward a fully multicalibrated predictor.
Efficiency comes from its use of any highly optimised gradient boosting library, such as LightGBM, which is used in the reference implementation. Safety comes from an early stopping rule that monitors validation loss: if a correction round would hurt performance, the algorithm stops and returns the previous model. The result is a post-processing tool that is fast, safe, and requires no hyperparameter tuning.
Scientific contributions
The novelty here goes beyond engineering pragmatism. MCGrad is the first multicalibration algorithm that requires no pre-specified groups, works out of the box, and guarantees it will not harm the base model. Alongside the algorithm, the paper introduces the Multicalibration Error (MCE), a new metric that for the first time directly corresponds to the formal definition of approximate multicalibration, giving practitioners a theoretically grounded way to measure what they are actually trying to improve.
Experiments across 11 public benchmark datasets show MCGrad outperforming all competing methods on multicalibration error in 10 of 11 cases, while also achieving the best average improvements in log loss and predictive performance. Unlike its competitors, it never degrades the base model, which is the property that ultimately convinced production engineers to trust it. In experiments on Meta's Looper platform, MCGrad was pitted against 27 live production models calibrated with Platt Scaling: it statistically significantly outperformed 24 of them and was promoted to primary production model in each case. Across a broader internal platform, it improved log loss for approximately 88% of models, precision-recall performance for 77%, and calibration error for 86%.
A companion paper, ‘On the Convergence of Multicalibration Gradient Boosting’ (Haimovich, Linder, Perini, Tax, and Vojnovic, 2026), co-authored by Professor Vojnovic, provides the first theoretical guarantees on the convergence of multicalibration boosting algorithms: the multicalibration error decays at O(1/√T) over rounds, improving to linear convergence under smoothness assumptions, with local quadratic convergence for adaptive variants. Together, the two papers offer a complete package of practical algorithm, empirical validation, and rigorous theory.
Deployed at web scale
MCGrad is not a research prototype. It is integrated into two of Meta's ML training platforms and currently powers over one million multicalibrated real-time predictions per second. To the authors' knowledge, this is the largest deployment of multicalibration anywhere in the world, and a significant milestone for the field of group fairness.
Now open source
The team has released MCGrad as an open source library at mcgrad.dev. The interface is as simple as the design philosophy: provide predictions, labels, and feature columns, and MCGrad does the rest. The same default configuration running at Meta generalises well across a wide range of datasets and settings.
This release brings the full benefit of the collaboration, algorithmic research sharpened by the demands of production at scale, to any team building ML systems that serve a diverse population. Academic rigour, industrial validation, and open availability: that is the combination that makes this work matter beyond the research community.
By Dr John Barlow, Engagement and Communications Lead, and Daniel Titherington, Enagement and Communications Officer, both at LSE Department of Statistics